If you look at the comments section of my blog entry here, there are quite a few users who have mentioned that the procedure did not work on their setup. One of the main reasons for that was that the changes being merged was not shown to the end user. Also, the procedure did not work for some of the earlier versions. So, i thought of blogging about another procedure that would basically merge only two repositories. If you had worked on the earlier releases of BI EE ( 7.8 or before versions ), you would have noticed that there was an option called Import from Repository. What this option basically did was it imported the objects from one repository into another. But this has been deprecated from 10.1.3.2 version of BI EE. Now the recommended way of getting one repository objects into another is to do a 2-way merge. Lets look at a step-by-step approach for achieving this. So basically our aim is to combine the contents of 2 repositories into a 3rd repository. The merge process would look like the one shown below
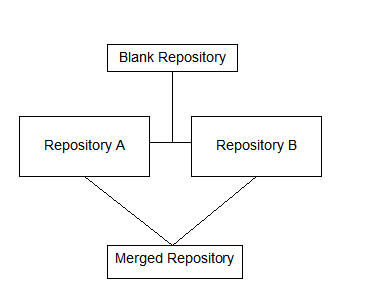
So basically, our idea is to use a blank repository as the baseline repository. Now, in our example we shall be using 2 repositories. One repository would be the default paint repository. The other would be the default bise1 repository. As the first step open up the paint repository in offline mode.
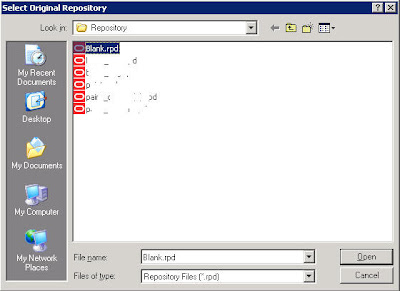
Then click on Merge. Specify a blank repository (create a repository which has no objects) as the original repository.
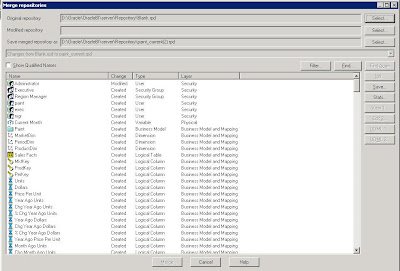
Once this is done, select the bise1 repository as the Modified Repository.
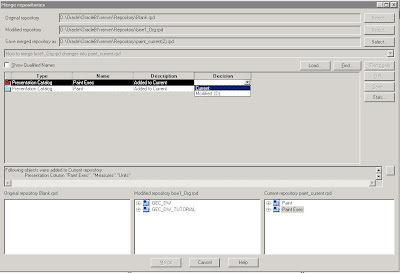
You would basically find the list of presentation catalogs, users, groups etc. In your case you would find either of the 2 descriptions below
Add to CurrentDelete from Current
When it is Add to Current, you can choose your decision as Current or Modified(D). If you choose current, the presentation catalog would be added to the repository. Else it would be deleted from the repository. Choose Current as the decision for all the “Added to Current” descriptions.
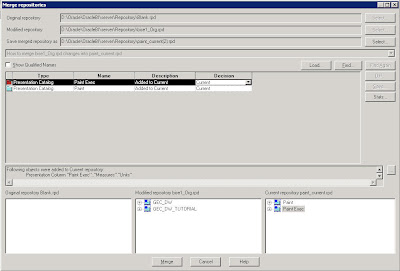
If you have Delete from Current, you would have to decide whether to add the objects to the repository or delete them. Now, click on merge. This should merge both your repositories properly.